
The Problem
Audio platforms are not designed to be social yet
Creating content on smart devices like Alexa and Google Home was really difficult to do. It included setting up a “Flash Briefing” in the Alexa Developer Console and updating a hosted JSON file every day to create a daily piece of content.
Audio memos on Whatsapp are easy to send but very hard to consume. People already “zombify” other platforms like Twitter for short-form audio content.
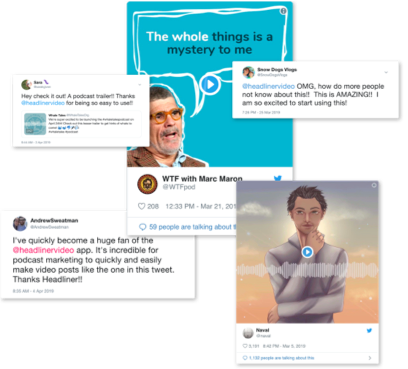
The average podcast is 43 minutes long and listeners have almost no possibility to interact with the creator.
Audio memos on Whatsapp are easy to send but very hard to consume. People already “zombify” other platforms like Twitter for short-form audio content.
The average podcast is 43 minutes long and listeners have almost no possibility to interact with the creator.
The Solution
Interactive voice memos
The first solution we created was a 100x faster way to set up your voice content for Amazon Alexa.
With that already solved and people using it daily for over a year, we wanted the platform to evolve into a “Twitter for voice”.
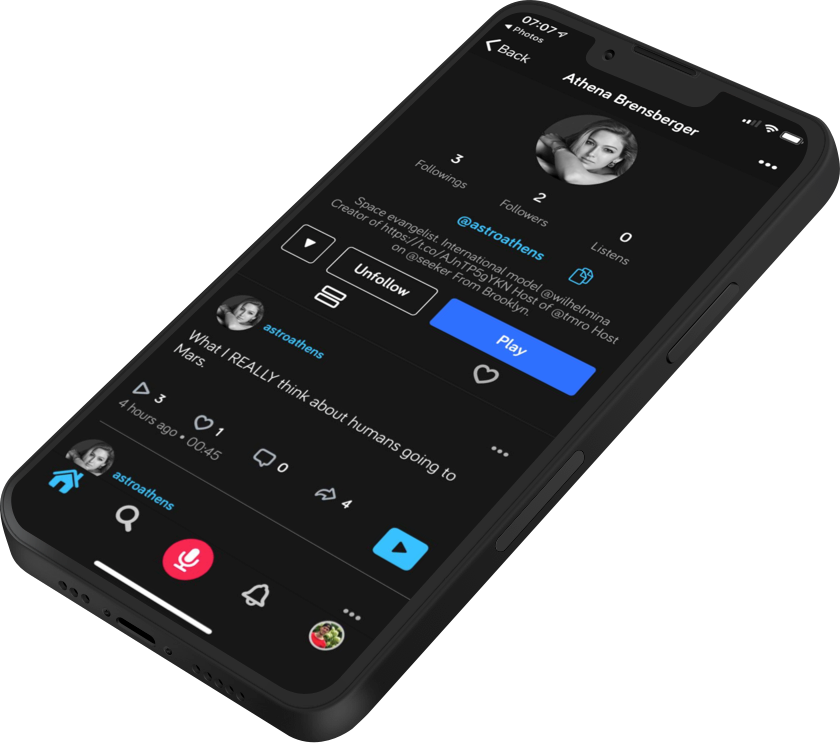
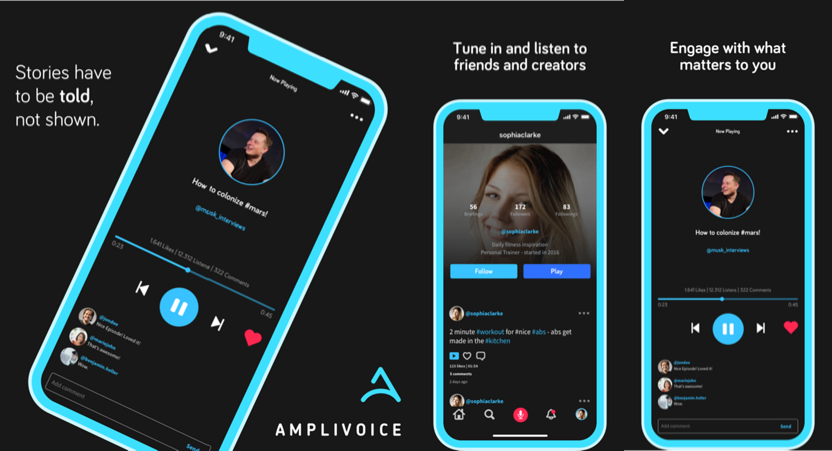
So we created a mix of Soundcloud, voicemails, Twitter and Podcasts called Amplivoice. It was an easy way to create and publish audio content and have the “classic” social network features like a feed, comments, like-buttons, and sharing options for other platforms.
With that already solved and people using it daily for over a year, we wanted the platform to evolve into a “Twitter for voice”.
So we created a mix of Soundcloud, voicemails, Twitter and Podcasts called Amplivoice. It was an easy way to create and publish audio content and have the “classic” social network features like a feed, comments, like-buttons, and sharing options for other platforms.
My Role
Co-Founder
My responsibilities were designing and developing the entire iOS app and backend development.
- User Experience
- iOS
- Infrastructure
- Design
- Prototypes
Tech Stack
Structure
Open for everyone, engage with an account
In order to let new users see what’s going on, we decided to make a dynamic sign up flow. People could already listen to posts from all users, but couldn’t engage without an account.

Working on a social app created many interesting aspects of development. Every stept had to be well thought through.
The Sign Up Flow had to be very simple and fast. We took inspiration from TikTok to also enable new users to listen to the content without signing up. In order to engage with the content and reply to posts, users had to sign up.
Posting a new piece of content was the most crucial part of the app. We have spent weeks building and testing different versions.
Our users could import audio files from other platforms, such as GDrive, and edit them before posting. It was also possible to import longer podcasts, trim them to the most important parts and then post these snippets.
Next, we focused on making listening to these posts very simple and fast. It was the first thing new users did in the app, so it had to be as smooth as possible, with a natural feel to it.
While listening, users could toggle the player, could queue up other posts and choose to listen from different playlists.
Building that was very exciting, but also very hard.
But probably the biggest factor was to allow content to be shared to other platforms. This was a key growth factor for Amplivoice. Let's look at this functionality.
Deep Dive
The Sharing Functionality
We wanted the sharing of content to be:
Easy to share to any platform with one tap
It was important to have multiple ways of consumption, so we created a video with sound and transcript
The design of the video had to catch attention and make it unique
Fast loading times (I guess that’s always important)
Now let’s dive deeper into how I’ve built the sharing functionality.
First, I’ve separated the process into easier steps:
This was the easiest part of the process and it is pretty self-explanatory. The user and post object were already in the cache.
We stored the transcript of each post with a Cloud Function in our database. The timestamps of each word were included, so we could highlight each word when it was spoken.
While the video was generated, we showed a modal view with a loading bar and the current step of the process to our users.
In total, we had 10 different ways to share a post. For some ways like Whatsapp or Messages, we just had to generate text with the link to the right post.
For Instagram, Twitter, Tiktok, and Facebook, we made it possible to share the video.
First, we created one image for every word. Each image had two lines of text, with the current word and past words highlighted in a color. The first step was to split up the transcript, so that the text fits on the image. After that, all the images were created.
We used a UIGraphicsImageRenderer for this.
Next, we used a AVAssetWriter to create a video out of these images. Since we stored the start and end time of each word, we could easily calculate the length each image had to be shown.
Now that we already had the transcript and layout in the video, we could easily:
This was also a straightforward task. We had a video and an audio file which we had to merge together. We used a AVMutableComposition with two tracks and exported the composition as mp4 file.
This was a bit tricky. In order to add an animated soundwave to the video, we used the AVMutableComposition as well, so we could add an animated layer to the video.
We stored the metering levels of the audio file when a new audio file got posted, so we also had them stored in the database.
Pew, the final step was to share this video. We had to write different code for each possibility to share the video.
First, I’ve separated the process into easier steps:
- Prepare the data for the video
- Get the right setup for each social platform (videos should have a different ratio on Instagram than on Twitter)
- Generate images with the transcript
- Create a video out of these images
- Add the audio file to the video
- Create a Soundwave and add it to the video
- Finish the video and share it
1. Prepare the data for the video
This was the easiest part of the process and it is pretty self-explanatory. The user and post object were already in the cache.
We stored the transcript of each post with a Cloud Function in our database. The timestamps of each word were included, so we could highlight each word when it was spoken.
While the video was generated, we showed a modal view with a loading bar and the current step of the process to our users.
2. Get the right setup for each social platform
In total, we had 10 different ways to share a post. For some ways like Whatsapp or Messages, we just had to generate text with the link to the right post.
For Instagram, Twitter, Tiktok, and Facebook, we made it possible to share the video.
3. Generate images with the transcript
First, we created one image for every word. Each image had two lines of text, with the current word and past words highlighted in a color. The first step was to split up the transcript, so that the text fits on the image. After that, all the images were created.
We used a UIGraphicsImageRenderer for this.
4. Create a video out of these images
Next, we used a AVAssetWriter to create a video out of these images. Since we stored the start and end time of each word, we could easily calculate the length each image had to be shown.
Now that we already had the transcript and layout in the video, we could easily:
5. Add the audio file to the video
This was also a straightforward task. We had a video and an audio file which we had to merge together. We used a AVMutableComposition with two tracks and exported the composition as mp4 file.
6. Create a Soundwave and add it to the video
This was a bit tricky. In order to add an animated soundwave to the video, we used the AVMutableComposition as well, so we could add an animated layer to the video.
We stored the metering levels of the audio file when a new audio file got posted, so we also had them stored in the database.
7. Finish the video and share it
Pew, the final step was to share this video. We had to write different code for each possibility to share the video.
The Results
700+ Users
We had over 700 signed up users in Amplivoice. In order to grow, we wanted to get investment and applied to several accelerators. While in New York, we met with potential investors like Gary Vaynerchuk and Esther Dyson.
My Co-Founder Alex and I were invited to Paris, were we had an interview at YCombinator.
Unfortunately we weren’t accepted to the accelerator and had to stop working on Amplivoice because we were running out of money.
My Co-Founder Alex and I were invited to Paris, were we had an interview at YCombinator.
Unfortunately we weren’t accepted to the accelerator and had to stop working on Amplivoice because we were running out of money.