
The Problem
Same problems with new ones added
There’s a lot we didn’t know about audio while working on Amplivoice.
We still thought about the same problems, as the low interaction rate on audio content.
Every social network generally faces the chicken-egg problem when starting out.
Without enough content, you won’t get new users.
Without enough users, there’s not enough content.
With Amplivoice we found out that the barrier of posting a short voice memo is still very high. There’s no better way to describe it, than “it didn’t feel right” to post something on there.
The hot new startup during the time we worked on Open was Clubhouse, also a voice social network focusing on live conversations with listeners.
We still thought about the same problems, as the low interaction rate on audio content.
Every social network generally faces the chicken-egg problem when starting out.
Without enough content, you won’t get new users.
Without enough users, there’s not enough content.
With Amplivoice we found out that the barrier of posting a short voice memo is still very high. There’s no better way to describe it, than “it didn’t feel right” to post something on there.
The hot new startup during the time we worked on Open was Clubhouse, also a voice social network focusing on live conversations with listeners.
The Solution
Copy what works and make it better
Clubhouse did a great job of solving the chicken-egg problem by its own mechanisms. The idea of it is to have a feed with “rooms” everyone could join. Everyone could host a room and invite speakers to have a conversation together. Other users could join in as listeners.
With this strategy, it’s possible to have endless content by only having two people talk.
We liked this strategy but also questioned a lot of features (and lack of features) designed by Clubhouse.
While working on Amplivoice we found out that it is very important to let introverted people feel invited to the network as well. So we integrated features like a live chat and “claps” for each speaker.
Clubhouse also had a weird choice in regards to their target audience. That’s why we wanted to create a natural place for Gen Z.
It’s no secret anymore that people want to choose how they look and how they want to identify. To create a space where this is possible, we included features like having Apple Memojis as profile pictures.

We also still believed in short audio memos, like we had at Amplivoice. That’s why we did a redo to make posting them easier.
The final result looked like this:
With this strategy, it’s possible to have endless content by only having two people talk.
We liked this strategy but also questioned a lot of features (and lack of features) designed by Clubhouse.
While working on Amplivoice we found out that it is very important to let introverted people feel invited to the network as well. So we integrated features like a live chat and “claps” for each speaker.
Clubhouse also had a weird choice in regards to their target audience. That’s why we wanted to create a natural place for Gen Z.
It’s no secret anymore that people want to choose how they look and how they want to identify. To create a space where this is possible, we included features like having Apple Memojis as profile pictures.
We also still believed in short audio memos, like we had at Amplivoice. That’s why we did a redo to make posting them easier.
The final result looked like this:
My Role
Co-Founder
My responsibilities were designing and developing the entire iOS app and backend development.
- iOS
- Server
- User Experience
- Design
- Prototypes
Tech Stack
Structure
Copy what works… again
We used the same approach as we did with Amplivoice.
Users should be able to get a sneak peek into the platform, to get a notice of its feel and navigation. In order to interact and speak, users needed to sign up.

We copied a lot of features from Amplivoice into Open.
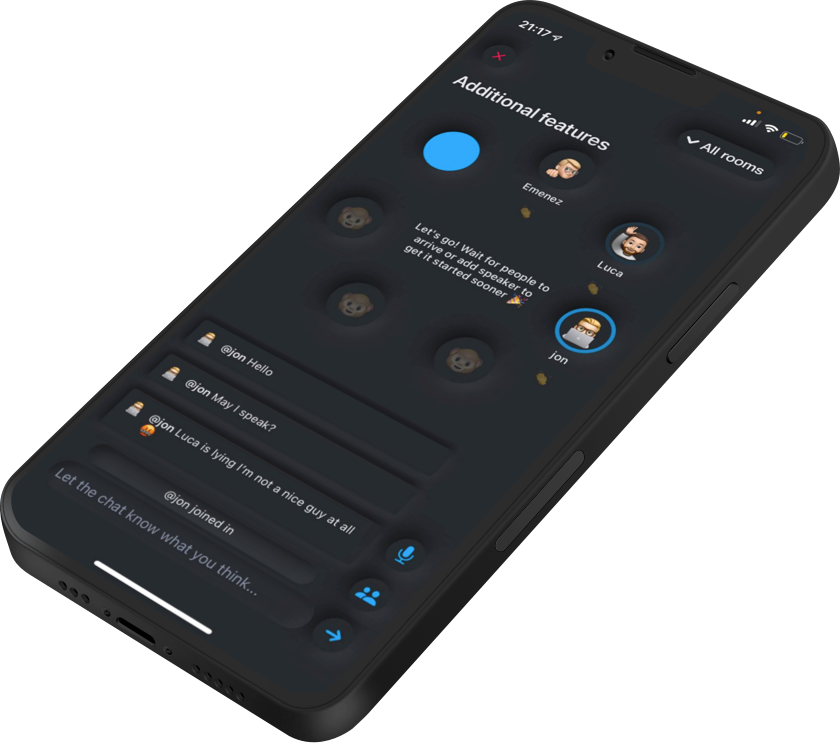
Instead of letting the feed show short voice memos, it showed the current rooms that were available to join.
We had one public room open where everyone could join as a speaker. Every user could also open another room and invite speakers.
Each user also had their own profile and users could follow each other. Users could also gather their thoughts into short audio memos and could select a combined emotion that would be displayed to other users.
Building the logic for audio rooms took the longest time.
So let’s take a deep dive into this:
Users should be able to get a sneak peek into the platform, to get a notice of its feel and navigation. In order to interact and speak, users needed to sign up.
We copied a lot of features from Amplivoice into Open.
Instead of letting the feed show short voice memos, it showed the current rooms that were available to join.
We had one public room open where everyone could join as a speaker. Every user could also open another room and invite speakers.
Each user also had their own profile and users could follow each other. Users could also gather their thoughts into short audio memos and could select a combined emotion that would be displayed to other users.
Building the logic for audio rooms took the longest time.
So let’s take a deep dive into this:
Deep Dive
Audio Engine
Since we wanted to have a way better audio quality than Clubhouse, we didn’t want to rely on a third-party service. Another reason to build our own engine was the costs, which could get very high with a call service that had to handle unlimited participants.
For these reasons, we wanted to build our own custom audio engine. It took a long time to get it to work as expected and it was really hard to test and debug.
Now let’s dive deeper into the engine. First, let’s clarify in detail, what we wanted to achieve:
Great Audio Quality
Low Latency to keep conversations natural
Small chunk size
Fast conversion of the audio buffer
Here’s a graphic to give you an overview on the structure of the engine:

In order to achieve our goals, we used these values for the audio conversion/compression:
- Format: MPEG-4 AAC ELD SBR
- SampleRate: 22050
- Bitrate: 48000
- Packet Capacity: 8
- Maximum Packet Size: 768
The RoomManager is the overarching manager to set up joining and leaving rooms. It holds one BufferAudioEngine, which handles everything audio-related.
This is where the fun begins.
We allowed up to 6 speakers in one room. This was to not confuse the listeners too much on who is talking in each room.
The BufferAudioEngine held a dictionary of user ids and SpeakerPlayers. If the current user was a speaker in this room, the BufferAudioEngine would also handle the recording.
We decided to use Apple's AVAudioEngine for recording and playing the audio.
Apple’s engine offers a lot of options to handle real-time audio and mix multiple layers of audio in one engine.
Each SpeakerPlayer held one AVAudioPlayerNode which the BufferAudioEngine connected to the AVAudioEngine. In that way, we were able to handle each speaker on their own. If there was trouble with someone’s internet connection, we could fix the latency for that particular speaker without causing trouble to any other speaker.
The RoomManager communicated with the Websocket and passed the data to the BufferAudioEngine. In there, the right SpeakerPlayer was found and the compressed data got converted into audio buffers and scheduled to play after the current audio buffer finished playing.
Since we also passed a timestamp for each buffer, we could check when this buffer was recording on the client-side of the speaker. If the buffer was older than 500ms, we changed the playing speed of that SpeakerPlayer, so the buffer would be played faster to catch up with the conversation. FaceTime uses a mechanism like that in order to keep the conversation in real-time.
We also had an upper limit of latency. If the limit was too high, the buffer wouldn’t be played anymore.
That resulted in a natural conversation with low latency by still having amazing audio quality.
Just record with the microphone… right?
There are a lot of challenges with the recording during a live conversation.What appears to be simple turned out to be way more complex. Especially in live conversation, there can be a lot going on.
Imagine someone sitting on a noisy train. Everyone in the room will hear the background noise and it lessens the experience of the conversation.
Or: Imagine someone not using headphones and listening to the conversation loudly while being a speaker. This will result in an awful echo.
So we had to process the input on the speaker's device. Fortunately, Apple has a built-in voice processor which we could just enable.
But this is not the only thing we had to do…
A more complicated aspect of recording was the different possible input devices. Apple handles them differently and you have to update the AudioSession for each option. Speakers could record via Bluetooth devices like AirPods, use the built-in microphone on the device, or plugin headphones with cables (yes, they still exist).
To handle the transitions, I reinitialized & reinstalled the input node to the audio engine.
Then there are interruptions…
For example: What if a speaker gets a phone call during a conversation?
This had to be handled as well. At one point we had a very weird, but cool bug (or growth hack?!). If a speaker of a room got a phone call, the caller could hear the entire conversation in Open, but wouldn't hear the speaker.
Due to Apple’s notification system, this was also handled in an easy way.
After a couple of weeks, we finally got the engine to work in a reliable way.
The Results
1200+ Users
With the room format on the rise, over 1200 people signed up for the app.
Since we founders had a different vision on where our platform was going, we agreed to stop working on this project and focused on other projects.
Since we founders had a different vision on where our platform was going, we agreed to stop working on this project and focused on other projects.